Chaperone
I built a basic but extensible monitoring tool to help people watch their systems. It's called Chaperone, and it's open-sourced on github. It's simple and powerful, letting you execute arbitrary scripts to determine health.
Why? #
A couple years ago, a bright colleague of mine whipped up a quick and elegant solution to watch and alert on a bunch of things running in our apps. We didn't want a big overblown solution, but it also needed to be customizable. I helped out a little. When the next suite of projects rolled around, I needed something similar. I could've reused the tool we had, but here's why I wanted to create something new:
- Almost every project needs something that can make basic monitoring easy, and custom monitoring possible. I was willing to make an investment of my own time to make something I loved for the long-term.
- Just about everyone these days is writing apps that are deployed as containers. Existing monitoring tools available were not built for this style of deployment, and didn't meet my goals. They're all built as these big centralized and costly to operate long-term installations, which doesn't fit in a decentralized app model where each team is reponsible for building and administering their own monitoring.
- The original tool was written in a language that isn't my favorite; this one's written in Kotlin, and my fondness for it encourages me to write more features with it.
What does it do? #
In a nutshell, you define a bunch of checks, and when the app starts up, it runs them periodically and sends the results to various places you configure.
More specifically, it runs every check you define as a bash command, and if the exit code of the command is zero, things are good. If it's non-zero, things are not good.
Isn't that what $SOME_OTHER_TOOL does? #
Yeahhhh...some tools do precisely that, some have a ton more features, some provide a giant user interface, and some cost a bunch of money. But whenever I looked for a tool, they all suffered from one of these flaws:
- too opinionated in how they worked
- a giant PITA to configure or run
- couldn't be configured to live alongside my project's source code
- too hard or confusing to configure and run as a container
What are the highlights of its features? #
Defining checks #
See the docs for the full list of features with examples, but basically you configure a check as a TOML config file and put that in a directory. If you're not familiar with TOML, it's a simple and obvious configuration file format. Here's the most basic example:
name = "basic example"
command = "ls"
interval = "1m"
timeout = "5s"
This example runs ls every minute. A more realistic example would be figurately stated as "curl some url and see if it returns a 200", which can easily be written as a one-liner. You don't need an HTTP-specific application for that.
A more advanced example is a templated check, where you run a "template" command that builds a list of dynamic checks, like "get a list of our running apps in the cluster", then "hit each app's health check url". e.g. Here's a real example we use in our project:
description = "app instance health"
# template will output $app-name $env $instance-id $health-check-url
template = "../scripts/list-instances.sh"
name = "$2 - $3" # the name of each check will be $app-name - $env. e.g. foo - dev
command = "../scripts/check-instance.sh" # call this command for each result from the template
interval = "1m"
timeout = "1m"
tags = {app="$1", env="$2", cat="app"}
The above example uses the concept of bash positional arguments as variables passed from the template to the command. If we had 10 instances running, it would dynamically execute 10 checks. It also uses tags to help organize our health check results.
Another real world template use case is "from our list of kafka topics, check if we can consume from each topic".
Outputting the results #
Result output capabilities is a pluggable model. There's a result OutputWriter interface with a single function fun write(checkResult: CheckResult), and so far two output destinations have been implemented:
- stdout - sends the results to stdout in a human-readable format
- InfluxDB - sends the results to InfluxDB. I'm currently using influx + grafana for our dashboarding and alerting, and it's been a great way to use tools we're already relying heavily on. For example, here's a sample grafana dashboard showing the results of some checks. You can find it and a sample grafana dashboard export in the example-usage section of the project.
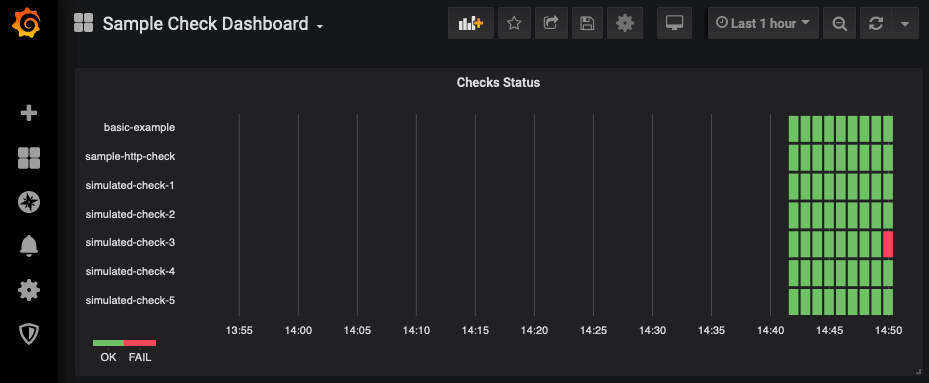
You choose the output options via a global config file that looks like this:
[outputs.stdout]
[outputs.influxdb]
db="metrics"
defaultTags={app="myapp-chaperone"}
uri="http://localhost:8086"
Some other ideas that haven't been built yet but would be pretty easy are destinations like:
- CSV file
- Common repositories like relational databases, other time series stores, etc...
- Custom destination - e.g. a script you've defined that accepts the results and does whatever with it, like put it in some crazy proprietary database you have.
How is it run? #
Chaperone itself is built and published as a docker image on docker hub. That's really just the shell though - the expectation is that you create your own docker container based on it, adding in your checks and then deploying that to your environment(s). Documentation on exactly how with a sample docker-compose file is included in the example-usage. Our team's naming convention for each checks source repository is $projectname-chaperone. Each chaperone definition project lives within the org it's watching, so it's version-controlled and happily living alongside the other org's applications.
Again, see the docs to try it out yourself. I made it with the intention that it's really easy to get going and use.
I also tried to make it easy to debug your checks as you build them, knowing that sometimes validation can get complicated. You can add a debug = true option to a check and it'll log out the commands as they're executed via the bash -x flag.
Feedback and ideas are greatly appreciated. As of this writing, there's a couple minor bugs and a few enhancement ideas in the backlog, but we've been using it in production for a while without major issue so far.
I plan to keep extending and investing in this project as long as it's useful to myself and others.
Thanks #
Thanks to Nathan Hartwell for his original ideas on the app. Even though I wrote it from scratch in a different language, I started with a lot of his ideas. Thanks to Ted Naleid for a great idea on how to make templated checks slicker. I also discovered some really nice utility libraries in this project; thanks to everyone that has contributed to them:
- CLIKT - kotlin command line interface handling
- Konf - This made parsing YAML configs super easy. It's a big and powerful project, and normally for smaller apps I'll use my own env-override, but Konf is really powerful and elegant.
- zt-exec - Command execution library. I started with implementing my own usage of ProcessBuilder, but there's a ton of ways to cut yourself. This has been both simple and sturdy.